Table of Contents
Recently, many users have encountered issues with Deepseek's servers being busy and unable to respond. Besides constantly refreshing and retrying, another solution is to deploy Deepseek on your local computer. This way, you can use it even without an internet connection!
DeepSeek from entry to mastery (Tsinghua University) PDF Downlod

Download Ollama
Website: https://ollama.com/
First, we need to use a software called Ollama. This is a free and open-source platform for running local large language models. It can help you download the Deepseek model to your computer and run it.

Ollama supports both Windows and MacOS. You can simply download it from the official website and install it with a few clicks. After installation, open your computer's command prompt (cmd) and type , then press Enter. If you see an output like the one shown below, it means the installation was successful.ollama

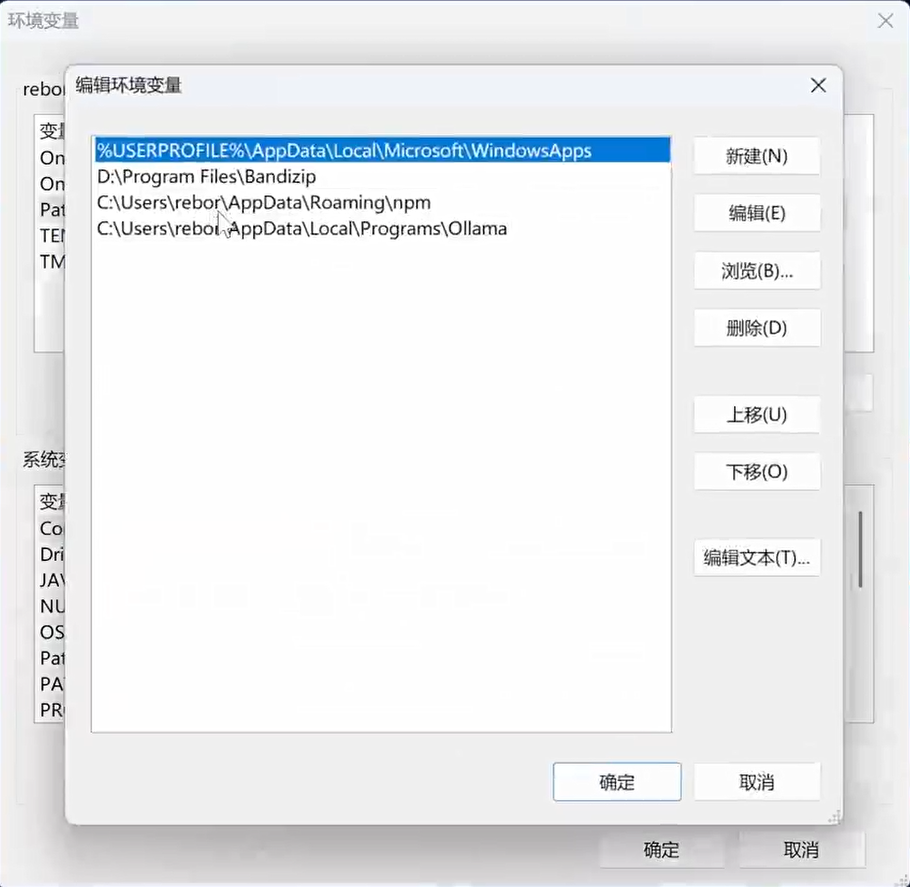
If you get an error saying the command is not found, check if the environment variable for Ollama's installation directory is configured in your system. If it is already configured but the error persists, simply restart your computer.
Download Deepseek Model
Next, go to the Ollama official website and click on deepseek-r1. This will take you to the Deepseek model download page. Currently, Deepseek-r1 offers several model sizes: 1.5b, 7b, 8b, 14b, 32b, 70b, and 671b.
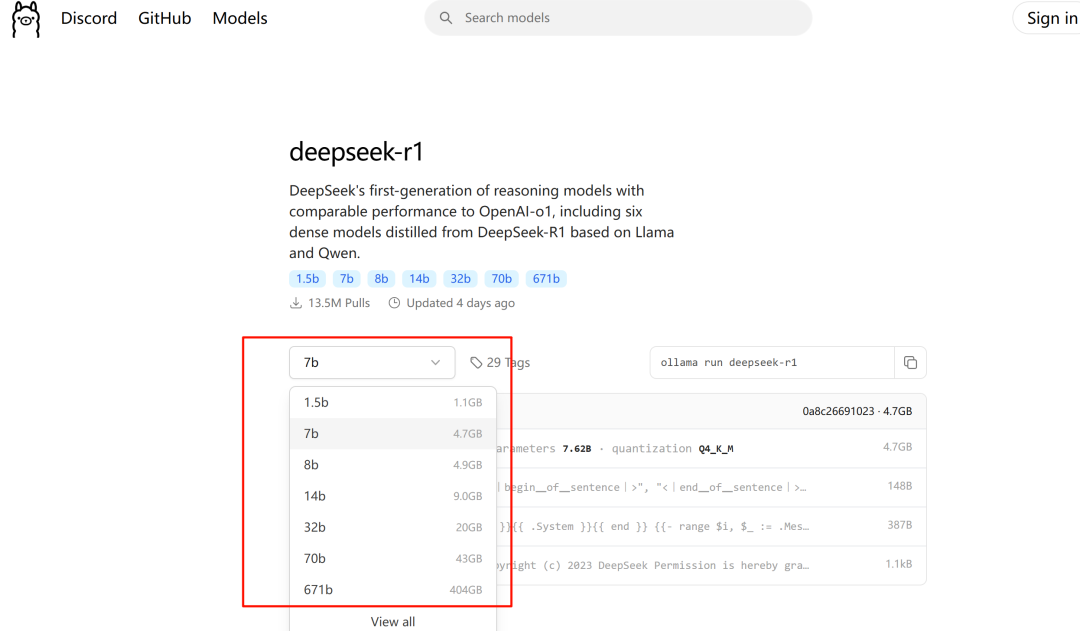
The number followed by "b" stands for "billion," indicating the number of parameters in the model. For example, 1.5b means 1.5 billion parameters, and 7b means 7 billion parameters. The larger the number of parameters, the higher the quality of the responses you will get.
However, larger models require more GPU resources. If your computer does not have an independent graphics card, choose the 1.5b version. If you have an independent graphics card with 4GB or 8GB of memory, you can choose the 7b or 8b version. Once you have decided on the model version, simply copy the corresponding command and paste it into the cmd terminal. Wait for the model to download and run automatically.
When you see the "success" prompt, the local version of Deepseek is deployed. However, at this point, you can only use it via the command line interface in the terminal, which is not very user-friendly. Therefore, we need to use a third-party tool to achieve a more conversational interface.

If you're passionate about the AI field and preparing for AWS or Microsoft certification exams, SPOTO have comprehensive and practical study materials ready for you. Whether you're preparing for AWS's Machine Learning certification (MLA-C01), AI Practitioner certification (AIF-C01), or Microsoft's AI-related exams (AI-900, AI-102), the certification materials I offer will help you study efficiently and increase your chances of passing.
Click the links below to get the latest exam dumps and detailed study guides to help you pass the exams and reach new heights in the AI industry:
- AWS MLA-C01 study materials (click this)
- AWS AIF-C01 study materials (click this)
- AWS MLS-C01 study materials (click this)
- Microsoft AI-900 study materials (click this)
- Microsoft AI-102 study materials (click this)
By achieving these certifications, you'll not only enhance your skills but also stand out in the workplace and open up more opportunities. Act now and master the future of AI!
Third-Party UI Client
Website: https://cherry-ai.com/
We recommend using Cherry Studio, a client that supports multiple large model platforms. It can directly connect to the Ollama API to provide a conversational interface for the large language model.
First, download and install the software from the official website. After installation, click on the settings in the lower left corner. In the Model Service section, select ollama. Turn on the switch at the top and click the Manage button at the bottom.
In the pop-up interface, add the Deepseek model you just downloaded. Then return to the main conversation interface, and you can start chatting with Deepseek.
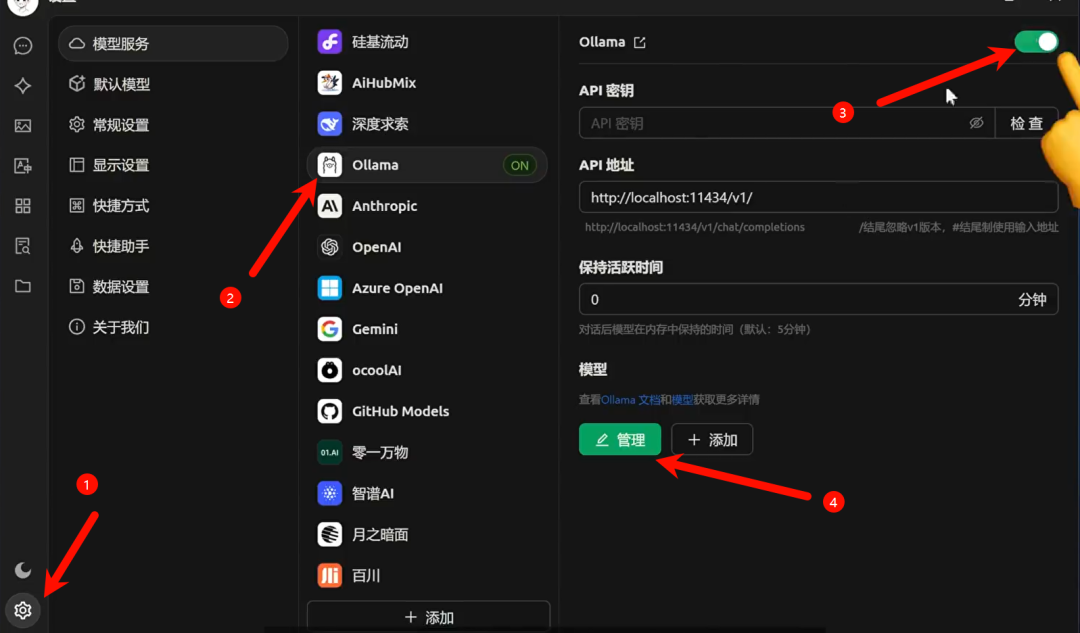
If you have installed multiple Deepseek models, you can switch between them by clicking on the top menu.
Model Testing
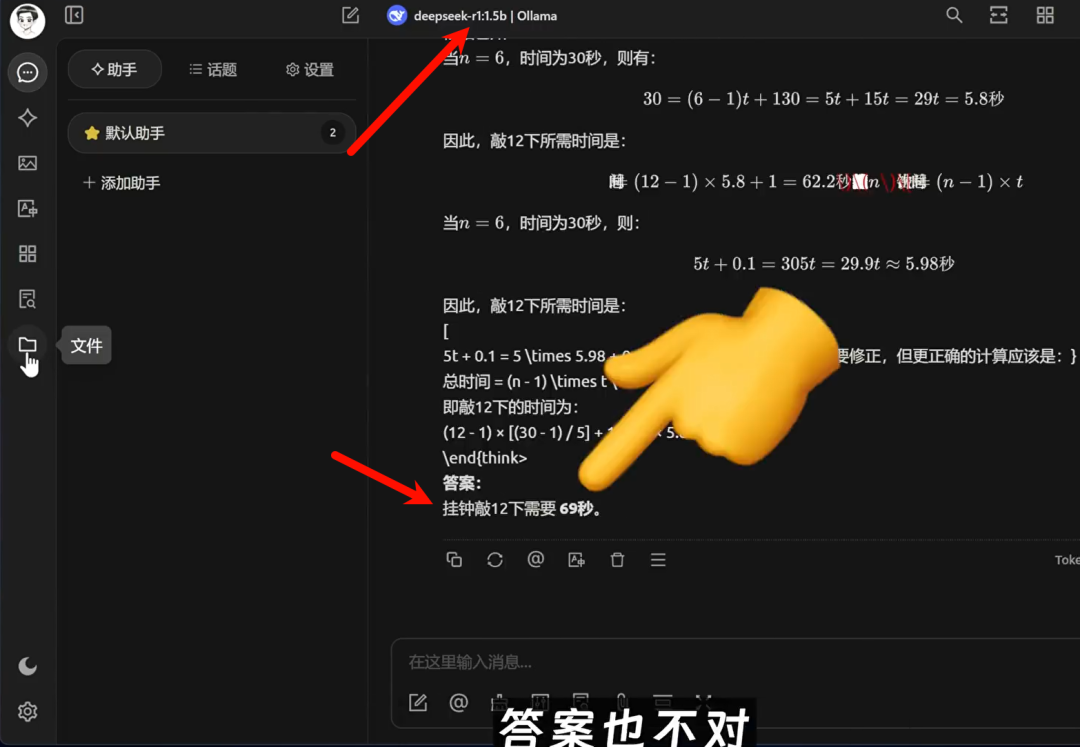
Let's test the quality of the model's responses with a simple question: "A clock chimes six times in 30 seconds. How long does it take to chime 12 times?" The correct answer is 66 seconds.
First, let's see the response from the 1.5b model. The response is very quick, but the answer is verbose and incorrect.
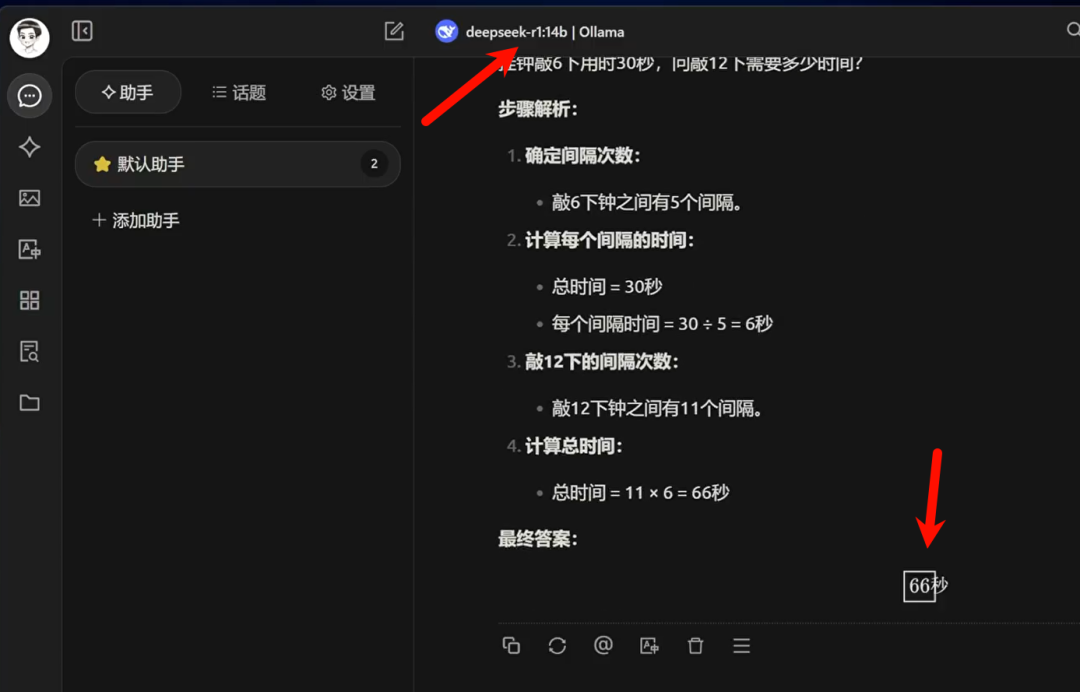
Next, let's look at the result from the 14b model. The response is concise and correct. It first determines the time interval for each chime and then calculates the total time for 12 chimes.
Hardware Requirements for Different Versions
1. Small Models
DeepSeek-R1-1.5B
-
CPU: Minimum 4 cores
-
Memory: 8GB+
-
Storage: 256GB+ (Model file size: approximately 1.5-2GB)
-
GPU: Not required (CPU-only inference)
-
Use Case: Ideal for local testing and development. Can be easily run on a personal computer with Ollama.
-
Estimated Cost: $2,000 - $5,000. This version is quite accessible for most people.
2. Medium Models
DeepSeek-R1-7B
-
CPU: 8 cores+
-
Memory: 16GB+
-
Storage: 256GB+ (Model file size: approximately 4-5GB)
-
GPU: Recommended with 8GB+ VRAM (e.g., RTX 3070/4060)
-
Use Case: Suitable for local development and testing of moderately complex natural language processing tasks, such as text summarization, translation, and lightweight multi-turn dialogue systems.
-
Estimated Cost: $5,000 - $10,000. This version is still within reach for many individuals.
DeepSeek-R1-8B
-
CPU: 8 cores+
-
Memory: 16GB+
-
Storage: 256GB+ (Model file size: approximately 4-5GB)
-
GPU: Recommended with 8GB+ VRAM (e.g., RTX 3070/4060)
-
Use Case: Suitable for tasks requiring higher precision, such as code generation and logical reasoning.
-
Estimated Cost: $5,000 - $10,000. This version is also achievable with some effort.
3. Large Models
DeepSeek-R1-14B
-
CPU: 12 cores+
-
Memory: 32GB+
-
Storage: 256GB+
-
GPU: 16GB+ VRAM (e.g., RTX 4090 or A5000)
-
Use Case: Suitable for enterprise-level complex tasks, such as long-text understanding and generation.
-
Estimated Cost: $20,000 - $30,000. This is a bit steep for someone with a $3,000 salary like me.
DeepSeek-R1-32B
-
CPU: 16 cores+
-
Memory: 64GB+
-
Storage: 256GB+
-
GPU: 24GB+ VRAM (e.g., A100 40GB or dual RTX 3090)
-
Use Case: Suitable for high-precision professional tasks, such as pre-processing for multi-modal tasks. These tasks require high-end CPUs and GPUs and are best suited for well-funded enterprises or research institutions.
-
Estimated Cost: $40,000 - $100,000. This is out of my budget.
4. Super-Large Models
DeepSeek-R1-70B
-
CPU: 32 cores+
-
Memory: 128GB+
-
Storage: 256GB+
-
GPU: Multi-GPU setup (e.g., 2x A100 80GB or 4x RTX 4090)
-
Use Case: Suitable for high-complexity generation tasks in research institutions or large enterprises.
-
Estimated Cost: $400,000+. This is something for the boss to consider, not me.
DeepSeek-R1-671B
-
CPU: 64 cores+
-
Memory: 512GB+
-
Storage: 512GB+
-
GPU: Multi-node distributed training (e.g., 8x A100/H100)
-
Use Case: Suitable for large-scale AI research or exploration of Artificial General Intelligence (AGI).
-
Estimated Cost: $20,000,000+. This is something for investors to consider, definitely not me.
The Most Powerful Version: DeepSeek-R1-671B
The 671B version of DeepSeek-R1 is the most powerful but also the most demanding in terms of hardware. Deploying this version requires:
-
CPU: 64 cores+
-
Memory: 512GB+
-
Storage: 512GB+
-
GPU: Multi-node distributed training with high-end GPUs like 8x A100 or H100
-
Additional Requirements: High-power supply (1000W+) and advanced cooling systems
This setup is primarily for large-scale AI research institutions or enterprises with substantial budgets. The cost is prohibitive for most individuals and even many businesses.
Conclusion
From this, we can conclude that the larger the number of parameters in the model, the higher the quality and accuracy of the responses. However, even if you use the 70 billion parameter version, it is still not the official Deepseek r1 model used on the website, which is the 671 billion parameter version.

Although the model size is only 400GB, to run this model locally, you would need at least four A100 GPUs with 80GB of memory each. This is impractical for most individuals. Therefore, the significance of running these smaller models locally is more about experimentation and experience.
For personal use, the 8b or 32b versions are more than sufficient. They can still function offline and will not encounter server busy issues, which is something the online version cannot match.