
 Join Telegram Study Group ▷
Join Telegram Study Group ▷











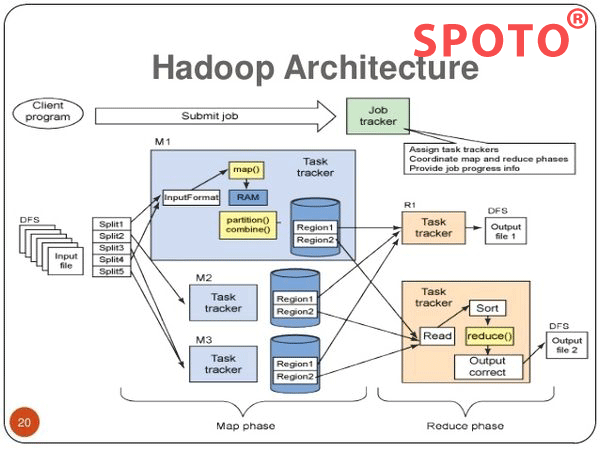

In the past, SPOTO simply talked about the SecondaryNameNode subnode and persistence in HDFS.In this article, the Secondary NameNode (Snn is written as SNN): Auxiliary daemons for monitoring HDFS status, taking snapshots of HDFS metadata at regular intervals.
SPOTO has a huge contribution to the big data technology and various certifications. Cisco has announced a big change in taking the certifications and SPOTO will give you the best support for your exam. The changes will be announced on 24, Fed,2020. SPOTO predicts that the exam will become more and more difficult, and the best time to take the certification is now. The following is some details of Hadoop.
First, about SNN
The main work of SNN
(1) The Secondary NameNode asks if the NameNode needs a checkpoint.
Bring it directly back to the NameNode to check the result.
(2) The Secondary NameNode requests to execute checkpoint.
(3) NameNode scrolls the edits log being written.
(4) Copy the edit log and image file before scrolling to the Secondary NameNode.
(5) The Secondary NameNode loads the edit log and the image file into memory and merges them.
(6) Generate a new image file fsimage.chkpoint.
(7) Copy fsimage.chkpoint to NameNode.
(8) NameNode renames fsimage.chkpoint to fsimage.
Second, persistence
After learning about the main work of SNN, let's talk about the working mechanism of SNN and NN, which is Namenode.
Working mechanism diagram of SNN and NN
Master a batch of metadata at NN (metadata is the data describing the data) - stored in memory
1. Hard disk, large memory, cheap but slow
2. Memory is small, expensive, but fast
2.1 What is persistence?
Persistence: To keep metadata safe, put the data in memory on disk.
When our cluster has problems due to special reasons such as power outages, the problem is solved, and when the power is turned back on, the metadata will be read on the disk and restored to the state before the power failure.
So why is it that NN can't be persisted?
In fact, we can say that NN can be persisted, or it can be said that it cannot be persisted. So when can I do persistence when I can't do persistence?
NN can do persistence: small demand, small memory usage, no impact on computing efficiency
NN can't be persistent: because NN itself has a lot of work, it is possible to take the opportunity in the process of persistence
Note: SNN can never replace the location of NN, he is just a hot standby for NN.
(Hot backup: work can still be done, but still can be backed up)
2.2 Edits and Fsimage
1. Fsimage: The file formed by serializing the metadata in the namenode memory.
2. Edits: Record every step of the client's update metadata information (the metadata can be calculated by Edits)
When namenode starts, it scrolls edits and generates an empty edit, then loads edits and fsimage into memory. At this point, namenode memory holds the latest metadata information. The client starts to add, delete, and modify the metadata of the namenode. The operations of these requests will be recorded in the edits first (the operation of the query metadata will not be recorded in the edits, because the query operation will not change the metadata information). If the namenode is hanged at this time, the metadata information will be read from edits after the restart. Then, the namenode will perform the operations of adding, deleting, and changing metadata in memory.
Since the operations recorded in edits will be more and more, the edits file will be larger and larger, which will cause the namenode to be slow when starting to load edits, so you need to merge edits and fsimage (so-called merge, which is to load edits and fsimage into In memory, follow the steps in the edits step by step, and finally form a new fsimage). The role of secondary namenode is to help namenode to merge the edits and fsimage.
The secondary namenode will first ask if the namenode needs a checkpoint (triggering the checkpoint needs to satisfy either of the two conditions, the time is up to and the data in the edits is full).
Persistent trigger conditions: Over 3600 or edits (edits.log) exceeds 64M
Bring the namenode back directly to check the result. The secondary namenode performs the checkpoint operation. First, the namenode scrolls the edits and generates an empty edit. The purpose of scrolling the edits is to mark the edits. All new operations are written to edits. Other unmerged edits and fsimages are copied to the secondary namenode. Local, then copy the edits and fsimage into memory for merging, generate fsimage.chkpoint, then copy fsimage.chkpoint to namenode, rename to fsimage and replace the original fsimage. Namenode only needs to load the previously unmerged edits and fsimage at startup, because the metadata information in the merged edits has been recorded in fsimage.
Summary: Persistence is to write the NN metadata to the disk for storage. When the NN is hung up, it will go to the disk to read the corresponding metadata and restore the state of the cluster----- Loss of electricity)
Power outage
Before persistence ------Start again, read the system log
After persistence ------- read the data on the disk, restore the state
Repeated power outage
There is a communication mechanism between the NN and the DN called the heartbeat mechanism. Every 3 seconds, the DN will send a heartbeat to the NN. If there is no heartbeat in 1 minute, the DN is considered to hang.

Then repeated power outages will enter safe mode:
Restore system status
Check DN information
Repair the problematic DN
1) In the process of transmission, the power is lost - data is lost. If the data is particularly important, it can only be pre-judged in advance and adjusted accordingly.
2) Power off after transmission is completed
When my cluster is restored, NN will read the metadata and restore the state accordingly.
3) If there is a problem with the DN. After the DN is restored, if a new task, depending on the situation, determine whether to upload a new file
